The U.S. States and Cities Where Residents Have the Biggest Vocabulary

Gotta catch ‘em all!
The English language has around 171,146 words in active use; most native speakers will use around 20,000. You can get by well in daily life with just 1,000 of them. But you are unlikely to excel at Scrabble unless you learn a few more (Hint: start by learning the two-letter words. “Em” is a valid one — though it refers to a unit of width rather than an abbreviation of “them”! “Gotta” is not a usable Scrabble word.)
But simply memorizing the Scrabble dictionary seems to miss the point (indeed, a conflicting figure suggesting we each know more than 42,000 words is based on recognizing legitimate sequences of letters rather than using them in context). The English language is rich and nuanced and often just downright entertaining. Who doesn’t want to color their conversation and writing with evocative yet precise vocabulary?
There are advantages on Twitter, too, since careful word choice is necessary to express your thoughts as clearly and boldly as possible within a limited character count. You may even pick up a few new words, although some might not yet be admissible on the Scrabble board.
So, Letter Solver turned to Twitter to discover where the biggest vocabularies in the U.S. are thriving — and analyzed location-tagged tweets to find which cities and states have the most diverse word usage.
What We Did
Letter Solver analyzed millions of geotagged English-language tweets. We selected tweets written in English, lemmatized* their content and divided all words into samples of 1,000. Finally, we obtained the number of unique words in those samples and calculated the mean number of unique words for each city and state.
* Lemmatize? “To reduce the different forms of a word to one single form, for example, reducing ‘builds,’ ‘building’ or ‘built’ to the lemma ‘build.’” There, your vocabulary’s growing already!
Key Findings
- Hawaii is the state with the biggest vocabulary, with Twitter users including 466 unique words per 1,000.
- Maryland is the state with the lowest vocabulary, at 432.7/1,000 unique words.
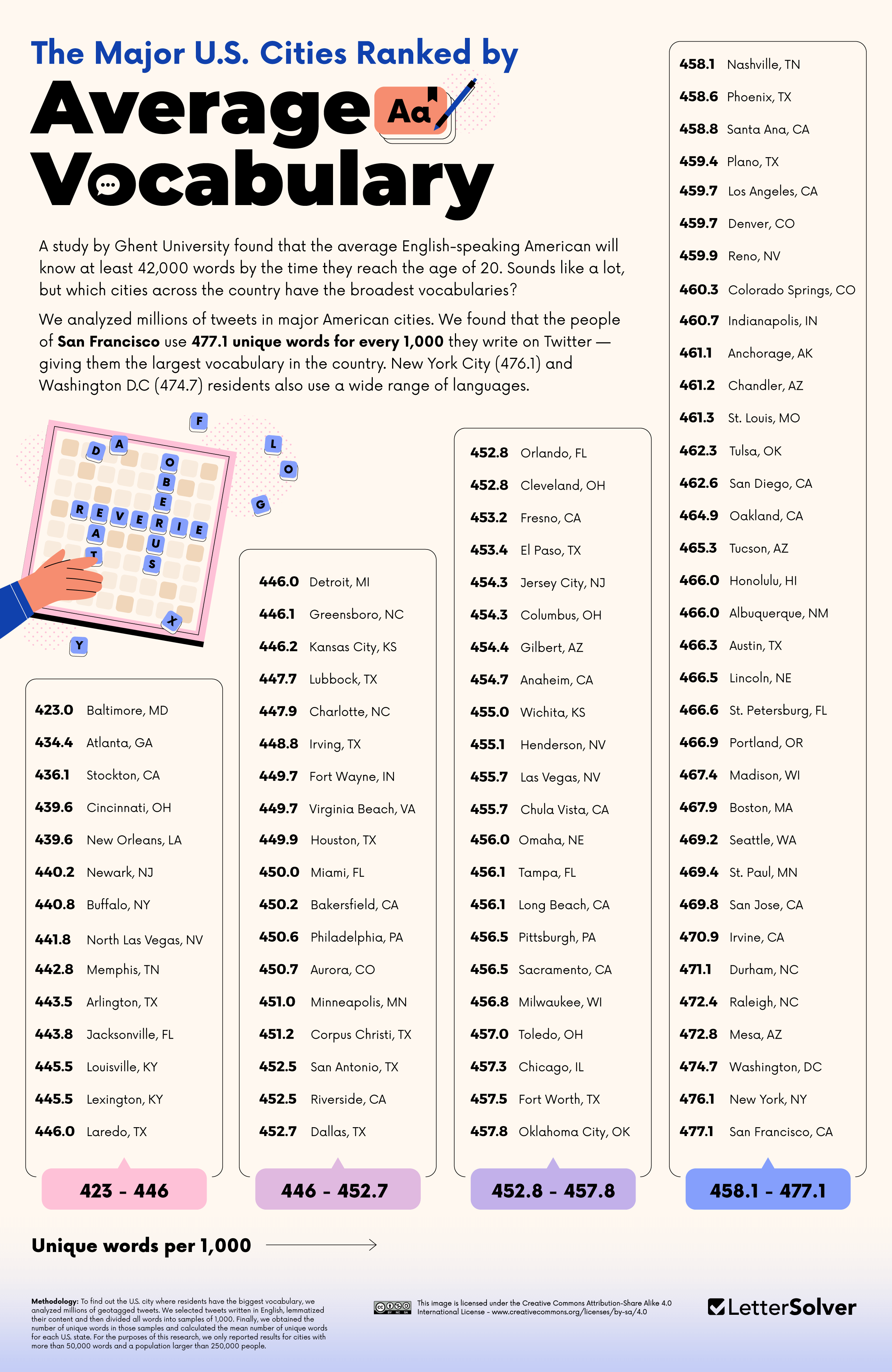
- San Francisco is the big city with the biggest vocabulary (477.1 unique words).
- The city with the smallest vocabulary is Baltimore (423 unique words).
Aloha Means Goodbye and Also Hello — Yet Hawaiians Use the Most Diverse English of Any State
America’s southeast tends towards a lower vocabulary, while the west of the country is relatively well-equipped in the word department. But the state with the biggest vocabulary is Hawaii, where 466 words out of every 1,000 tweeted are ‘one-offs.’ Hawaiian and English are both official languages of Hawaii. Since bilingualism is known to promote cognitive strength and versatility, and kids who grow up speaking two or more languages outperform others in English by the age of seven, it is possible that being raised in such an environment boosts locals’ grasp of diverse English vocabulary.
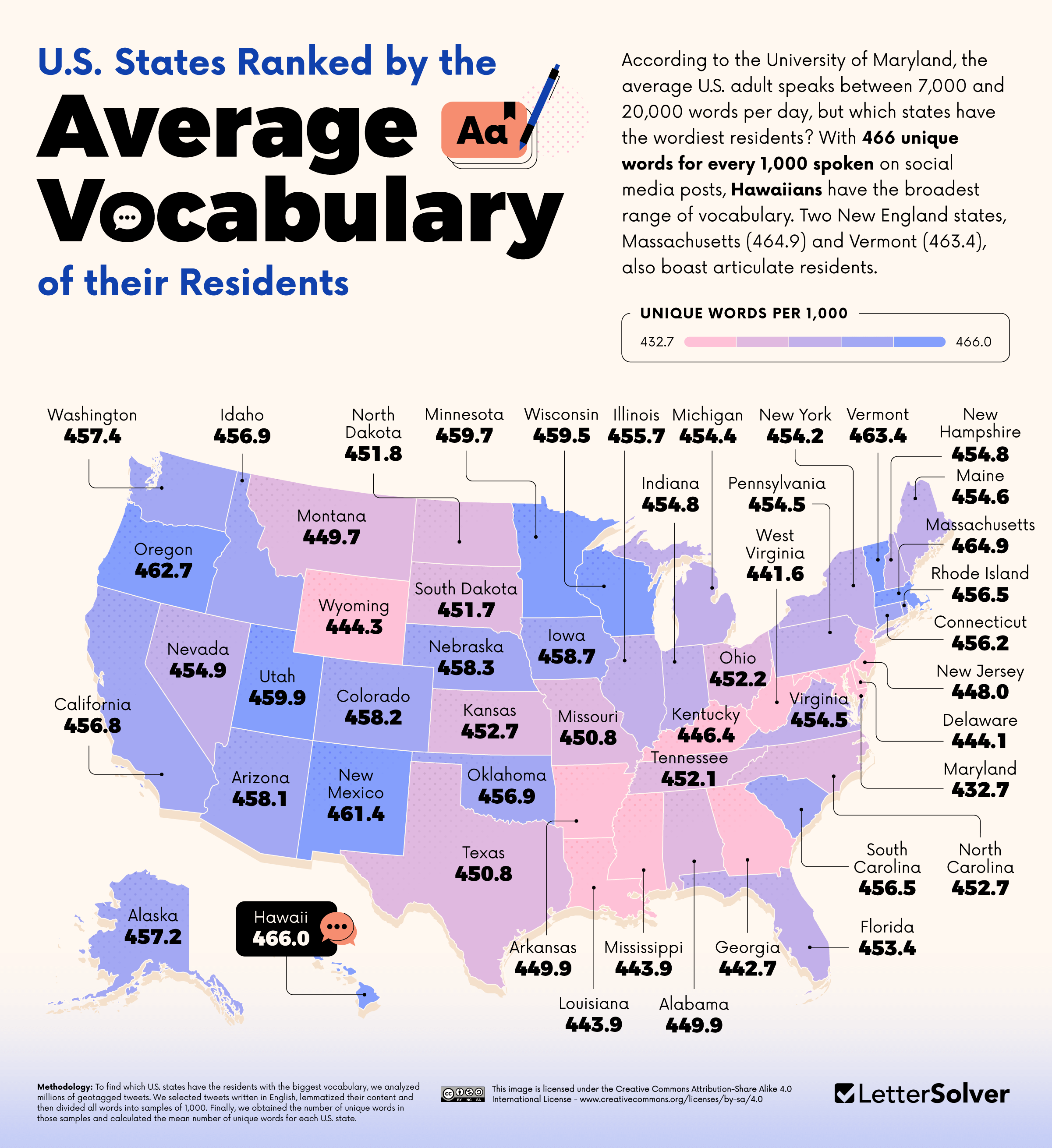
Hawaiians use nearly 13 unique words per 1,000 more than the national average. While there are other bilingual areas of the U.S., it could be the nature of the Hawaiian language that promotes a rich English vocabulary on the island. “Hawaiian language is very poetic, often utilizing comparisons to nature or natural phenomenons,” tweets the Hawaiʻi Tourism Authority — itself exhibiting a strong vocabulary. “These sayings, or ʻōlelo noʻeau, can be used to convey lessons on morality or proper behavior, knowledge on environmental observations, and encapsulate a uniquely Hawaiian world view.”
San Francisco is America’s Most Eloquent City
Next, Letter Solver looked at cities with a population greater than 250,000. Here, we found an even greater divide between cities with the largest (San Francisco, 477.1) and smallest (Baltimore, 423.0) vocabularies. And this, despite one of Baltimore’s most famous Twitter users, The Wire writer David Simon, having one of the most celebrated vocabularies on the website (his collected insults and neologisms are here, though it's deeply NSFW and few of the words are legitimate Scrabble fodder). “When I try to go ornate for laughs,” tweets Simon, “I'm really nicking guys like Perelman, Wodehouse and Mencken. Over-the-top vocabulary and clause-heavy sentence structure.”
San Francisco recently enjoyed a visit from representatives of the Bureau of Linguistical Reality, an artist duo attempting to “co-create a new lexicon for a time of climate change, biodiversity collapse and other transformations in the natural world.” Inspired by the area’s front-line experience of coastal erosion and rising tides, they coined words that may fuel locals’ future tweets, such as sandulate (“to understand that the coast is alive, and we can't just build the solid structures that we have”) and mientierra (“a false sense of solid ground beneath us”).
Twitter: The Place Where Words Are.
If you believe raw wordage to be your city’s most valuable resource, you can use the interactive table below to check how local vocab adds up on Twitter — and to compare your score against other cities in your state.
Meanwhile, there’s no debate over the Twitter user with the biggest vocabulary. No, it’s not David Simon but the retired @everyword bot, which claims to have “Twittered every word in the English language” one by one between 2007 and 2014. Perhaps improbably, its creator Allison Parrish later published the collected tweets as a book. “At long last,” said one sarcastic reviewer, “every word in the English language compiled in a single volume.”
Now, what could you do with a book like that?
METHODOLOGY & SOURCES
To find out the U.S. states and cities where residents have the biggest vocabulary, we analyzed
the content of millions of geotagged tweets. We selected tweets written in English, lemmatized
their content and then divided all words into samples of 1,000. Finally, we obtained the number of
unique words in those samples and calculated the mean number of unique words for each city
and U.S. state.
The geotagged tweets were obtained on a city level — then they were grouped by state to produce
state-wide results.
We lemmatized the words of the tweets using Python library Spacy. Then, all lemmatized words were checked against NLTK's word collection and 1,000+ common English slang words to ensure quality.
In case multiple tweets from the same account were present on the sample, we limited the number of tweets per account to 20, prioritizing the most recent ones.
For the geospatial data, we calculated the distance between each pair of cities as a straight line that
joined each city's center. We considered the central point on each city's bounding box as its center.
The data was collected in January 2023.